2. Describing Data with Tables and Graphs
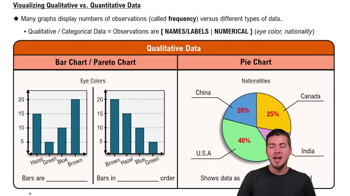
Visualizing Qualitative vs. Quantitative Data
Problem 2.CQQ.9
Textbook Question
Seatbelts The Beams Seatbelts company manufactures—well, you know. When a sample of seatbelts is tested for breaking point (measured in kilograms), the sample data are explored. Identify the important characteristic of data that is missing from this list: center, distribution, outliers, changing characteristics over time.
 Verified step by step guidance
Verified step by step guidance1
Step 1: Begin by understanding the characteristics of data listed in the problem: center, distribution, outliers, and changing characteristics over time. These are key aspects used to describe and analyze data in statistics.
Step 2: Recall that another important characteristic of data is its **spread** or **variability**, which measures how much the data values differ from each other. Spread is often quantified using measures like range, variance, or standard deviation.
Step 3: Consider why spread is essential. It provides insight into the consistency or variability of the breaking points of the seatbelts. For example, a high spread might indicate that some seatbelts are much weaker or stronger than others, which could be a concern for quality control.
Step 4: Reflect on how spread complements the other characteristics. While the center gives a single value summarizing the data, spread helps to understand the overall reliability and predictability of the seatbelt breaking points.
Step 5: Conclude that the missing characteristic from the list is **spread** or **variability**, as it is a fundamental aspect of data analysis that helps in understanding the range and consistency of the data values.
Verified video answer for a similar problem:This video solution was recommended by our tutors as helpful for the problem above
Video duration:
2mWas this helpful?
Key Concepts
Here are the essential concepts you must grasp in order to answer the question correctly.
Variability
Variability refers to how spread out or dispersed the data points are in a dataset. It is crucial for understanding the range of values and the degree of differences among the measurements, such as breaking points of seatbelts. High variability indicates that the data points are widely spread, while low variability suggests they are closely clustered around the center.
Recommended video:
Guided course
 07:09
07:09Intro to Random Variables & Probability Distributions
Center
The center of a dataset is a measure that indicates the central point around which the data values are distributed. Common measures of center include the mean, median, and mode. Understanding the center helps in summarizing the data and provides a reference point for comparing other statistics, such as variability and distribution.
Recommended video:
Guided course
 04:48
04:48Comparing Mean vs. Median
Outliers
Outliers are data points that significantly differ from the rest of the dataset. They can skew the results and affect the measures of center and variability. Identifying outliers is essential in data analysis, as they may indicate errors in data collection or unique cases that require further investigation.
Recommended video:
Guided course
04:48Comparing Mean vs. Median
 4:39m
4:39mWatch next
Master Visualizing Qualitative vs. Quantitative Data with a bite sized video explanation from Patrick
Start learning